Chonky Boys Contains Wisdom
What is hidden inside the weights of a randomly initialized neural network?
If you want to dive headfirst to the code, you can directly go here
Earlier this week, a researcher i followed on twitter retweeted this thread written by another researcher.
The paper mentioned can be accessed through This link. After reading the abstract and eventually the whole paper, i found the idea to be pretty cool and i wanted to give it a go myself.
TL;DR of the paper : Chonky bois (wide, randomly initialized neural nets) contains wisdom (a subnetwork that performs well on a given task)
The main idea of the paper is that, hidden inside a randomly initialized neural network is a subnetwork that can reach good performance on a specified task, similar if not better in performance with a trained model. But the problem is, because all the possible combinations, the number of subnetworks within a singular network will be huge. This makes it more and more unlikely to find the right, or let’s say, the good enough subnetwork to achieve our goal, sadly. But, the possibility is still not zero. Let’s rewind a bit.
The idea of optimizing a neural network without changing the weights has been explored in many papers, the most recent i read (and also mentioned in the paper explained in this post) is the Weight Agnostic Neural Networks (WANN) which performs architecture search on a fixed value for all weights to reach good performance on certain tasks. But i digress. Probably in the future i will try to implement that too because frankly it is a cool idea.
So, how do we find our needle in a haystack? Let’s say, we already have our network. For simplicity’s sake, I’m gonna use a Fully-Connected Neural Network as an example. How do we decide, which subnet is the best for our use case? The answer is left for the diligent readers as an exercise.
Psyche. The approach mentioned in the paper is to assign for each individual weights of the network their own scores. During feedforward, for each layers, only the top K-% weights with the highest scores are used. The rest are zeroed out. In this paper, only the weights are considered, and all kinds of biases (including the ones in BatchNorm) are not used.
This equation kinda describes what happens during feedforward (if you are the mathy type i apologize if how i use the notation offends you lmfao) :
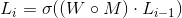
With L_i being the output vector of the ith layer, W being the weights, and M being the mask for the weights. The weights, scores and mask all have the same dimension. The mask contains only 1 and 0. 1 where the score (that corresponds to a weight value in the same position) is among the top-K% highest, 0 otherwise.
So far so good. But the scores are random, too! How do we make sure that eventually, the right scores will be assigned to the relevant weights?

But dude, you said we won’t update the weights! What is the gradients for?. Yes, nice observation. Normally, we use the gradients of the loss function with respect to the weights to perturb the weights in the correct direction to slowly but surely adjust the weights so our loss decreases over time.
Nobody said we can’t do that for the scores right? To update the weights, we find the gradients of the loss function with respect to the scores to update the score in the same manner we update the weights on normal weight training. Yay! We made it! Right? Right. Unless…
Recall that the Mask M depends on the scores being the top-K% or not, and it only has 2 possible values, 1 and 0!
As the result, the gradient is 0, on both sides! Now what? we can’t really backpropagate through this, can’t we?
This is why, in the paper, the authors estimates the gradient using a straight-trough estimator. Which means the gradients will pas straight through the mask and directly into the scores. Outstanding move. In the future, better scoring segments could be explored, but looking at the results on the paper, they are good enough.
Now we have it. We know how to run the forward pass and backward pass, and we now have the gradients w.r.t the scores. Just grab an optimizer, chuck in the params and the gradients, and call it a day.
TL;DR so far
- Weights are NEVER updated.
- Bias aren’t used.
- Each weights are assigned their own scores.
- During forward pass, only weights whose score is among the top-K% is considered. The rest are zeroed out.
- To update the scores so that the right weight will be selected, we calculate the gradient of the loss function w.r.t the scores, and update them all the same.
Important parameters to note, from the paper
- The value of K is important, and for simplicity is the same for every layers. generally K between {30,70} is good. Too much, the prediction will be random. Too little, not enough power.
- Wider, the better. This gives the model more parameters and possible subnetworks to choose from. But it does not come from just having more parameters. Observations made in the paper shows that even at the same parameter count (by adjusting the K), the performance is still great! Even closer to the performance of a model trained normally.
- Weight initialization matters. The Kaiming Uniform and its scaled variant gives the best result as observed on the paper.
Ok, thanks. Very cool. Can i see the code now?
I thought you’d never ask. (in reality you probably don’t because im asking this question myself) For the implementation, i used numpy (and later, cupy to speed things up because i suck at optimizing) because in my framework of choice (TF2/Keras) I Couldnt figure out how to cleanly specify my own backward flow. And i am not in the mood to learn pytorch so there’s that.
Code is long and IMO p self-documented. Do go straight to the notebook!
On my experiment, i used the same number of hidden layers for both variants. The only different is the width. While the normal NN has sizes of [784,100,100,10], for the Score NN i used [784,250,250,10] with K being 50%, balanced as all things should be. I also used the same loss function, the same initializer and the same optimizer for both variants. Even batch size and no. of epochs are also the same. Difference only in alpha (learning rate) because seems like the scores can be trained using higher learning rate (implications of faster convergence?).
At the end of the experiment, the normal NN achieves 97.5% on training data and 95.5% on test data, while the score NN achieves 93.3% accuracy ontraining data and 92.26% on test data. (Maybe the lower disparity between the train and test scores of score_nn signifies something?) Which shows that it is possible to utilize the random weights of a NN by finding the right subnetwork utilizing them.
Welp, that is all. Thank for coming to my TED (actually not) Talk (actually a monologue).
Stay classy.